
Hadoop and .NET: A Match Made in Docker
Want to write MapReduce jobs for Big Data in C# and execute them on a Hadoop cluster running Linux? Now that .NET Core 1.0 is RTM, we can do it. And thanks to the .NET community a huge number of NuGet packages already have .NET Core support, so there’s a good set of libraries for transformation already available.
I’m covering this in my upcoming Pluralsight course, Hadoop for .NET Developers , and in this post I’ll show you how to run .NET MapReduce jobs without having to install Hadoop, by using my Docker image.
Short version: sixeyed/hadoop-dotnet image on the Docker Hub
Hadoop and .NET
Actually I’m talking about .NET Core. That Docker image is built on Debian Jessie, and it installs Hadoop and .NET Core. You can run compiled .NET Core assemblies just by running dotnet /path/to/my/assembly.dll. The same image can run as Hadoop master and worker nodes, so all workers have .NET Core installed and can run .NET Core apps.
Which means you can run .NET Core apps as mappers or reducers in Hadoop jobs, thanks to the Hadoop Streaming interface. Hadoop Streaming lets you shell out to any program the host can execute, to run the tasks for your job. Your code integrates with Hadoop at a basic level - through the standard input and output streams.
To use .NET for MapReduce, write your mapper as a .NET Core console app; you receive input from Hadoop in a Console.ReadLine() loop, and you write back to Hadoop using Console.WriteLine(). Similarly, your reducer is another console app which receives the shuffled intermediate output from Hadoop, and writes out the final aggregations.
When YARN schedules a task to run, the worker node which executes it still fires up a Java Virtual Machine to communicate with the Application Master, but that JVM spawns a new process which runs the .NET Core app, and manages the transfer of data between stdin and stdout.
You can run full .NET Framework MapReduce jobs if you run a Windows distribution of Hadoop like Hortonworks HDP or the Syncfusion Big Data Platform. I cover that too in the new course, so stay tuned on Twitter to hear when it gets released.
Running a Hadoop Cluster with Docker
Spinning up a cluster using Docker lets you get up-and-running very quickly, and it also lets you use the exact same environment for local development and for testing.
I have a simple Docker Compose file for running a two-node cluster (although in the course I use four worker nodes), and assuming you have Docker and Docker Compose installed - you can spin that up by running:
wget https://raw.githubusercontent.com/sixeyed/dockers/master/hadoop-dotnet/docker-compose.yml
docker-compose up -d
Once the image has downloaded (it’s 988MB , but hey - it has Hadoop and .NET Core installed), the containers will start in a few seconds, but it will take a minute or two for the cluster to shake itself up and come online. The normal Hadoop Web UI ports are exposed, so you can check HDFS with http://docker-machine-ip:50070 and YARN with http://docker-machine-ip:8088.
When it’s ready, you can copy your data and binaries into the container.
A .NET Core Mapper
The Hadoop Streaming interface is super simple for mappers. Your console app receives one line of input at a time, you extract the data you want and write it out.
Here’s a simple example of the main method in a Program.cs, which picks the third field from a line of CSV input:
public static void Main(string[] args)
{
var line = Console.ReadLine();
while (line != null)
{
using (var reader = new StringReader(line))
using (var parser = new CsvParser(reader))
{
var fields = parser.Read();
Console.WriteLine(fields[2]);
}
line = Console.ReadLine();
}
}
Those
usingstatements are important as your .NET Core app will run for a whole Hadoop file block, and you should use your resources carefully. But you should always follow IDisposable best practices anyway.
The CsvParser class comes from the CsvHelper package on NuGet, which has been ported to .NET Core. JSON.NET has been ported too, and you’ll find most popular libraries are already available to you.
When you package your mapper with dotnet publish you’ll get a set of DLLs and config files like this:
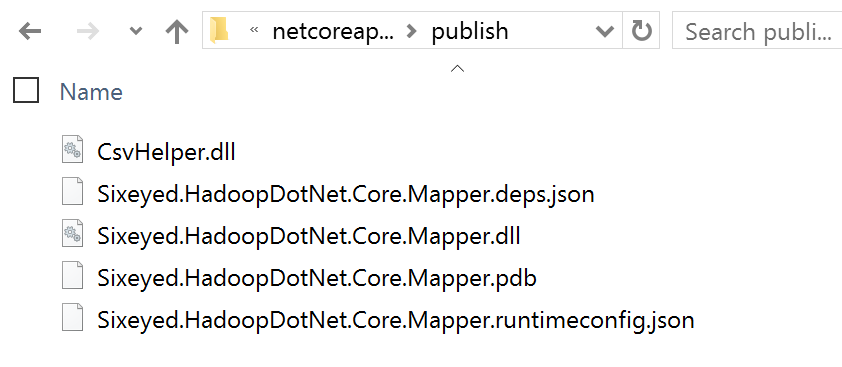
That’s what you’ll copy to the container to run as your mapper.
A .NET Core Reducer
The reducer is a bit more complex, because the streaming interface doesn’t receive an array of values for each key like you get with a Java reducer. Instead you get a flattened input, with one key-value pair in each line.
Reducer input is still sorted, so you need to maintain state in your .NET app, but you know when the key changes that the previous key’s data is complete and you can write it out.
This is how a .NET Core reducer looks - this example just sums up all the key occurrences (note how cool stuff like string interpolation in C# 6 is available in .NET Core):
public static void Main(string[] args)
{
string key = null;
var count = 0;
var line = Console.ReadLine();
while (line != null)
{
if (line == key)
{
count++;
}
else
{
if (key != null)
{
Console.WriteLine($"{key}\t{count}");
}
key = line;
count = 1;
}
line = Console.ReadLine();
}
Console.WriteLine($"{key}\t{count}");
}
The mapper and reducer tasks could run on any node, so it makes sense to combine all the assemblies and dependencies in one folder, which will be copied to the worker nodes when the job runs:
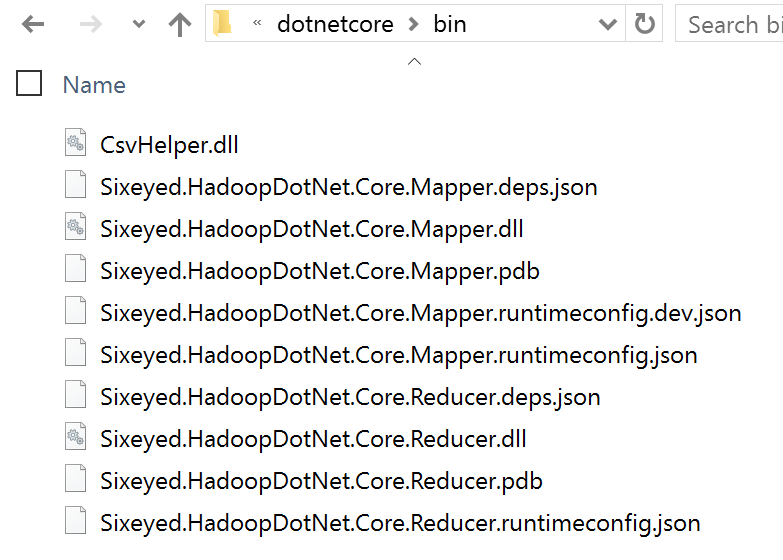
Copying Files to the Cluster
For your sample data, you’ll need to copy the file(s) to one of the Docker containers, and then put the files from local storage on the the container into HDFS.
In this example, I copy a file called data.csv from the current working directory on the host to the root of the Hadoop master node, and then into the input folder in the HDFS root:
docker cp data.csv hadoop-dotnet-master:/data.csv
docker exec -it hadoop-dotnet-master bash
hadoop fs -mkdir /input
hadoop fs -put /data.csv /input/
For the .NET Core apps, you just need to copy them to the container - when you run the Hadoop Streaming job, you’ll specify a local folder to ship and Hadoop will take care of making it available in the working directory of the nodes.
docker cp bin hadoop-dotnet-master:/dotnetcore
Now the data you want to query is in HDFS, replicated across the nodes in your cluster, and the console apps which will execute the mapper and reducer tasks are on the master container, so you’re ready to launch the job.
Running a .NET Core MapReduce Job
OK, this is the big one. All Hadoop installations come with the streaming JAR, and the current sixeyed/hadoop-dotnet image is tagged 2.7.2, the Hadoop version which forms part of the JAR name.
To submit the job, you run something like this:
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar \
-files "/dotnetcore" \
-mapper "dotnet dotnetcore/My.Mapper.dll" \
-reducer "dotnet dotnetcore/My.Reducer.dll" \
-input /input/* -output /output
And then you’ll get the usual output from Hadoop, but as the UI tracks the job progress, you’re getting a report of the tasks which are running .NET code! Woot!
The files argument copies the whole folder containing your .NET app to the working directory of the node executing the task, so the mapper executable contains the dotnetcore folder name.
Big Data and Small Containers
This is a fantastic use case where three great technologies are making new things possible. Hadoop development has always had a pain point where development environments don’t match test, and for a decent test environment you needed a dedicated set of machines.
With Docker you can use an image to run a real distributed cluster on your dev laptop, and the same image to run a test environment on a swarm of Docker machines. That swarm in your test lab doesn’t need to be dedicated to Hadoop - you can spin your cluster down when you’re not actively testing and use the compute for other work.
And now we have a cross-platform .NET implementation, MapReduce jobs can be written in C# with all the goodness of Visual Studio (Code or full), and NuGet available to us.
Hadoop is 10 years old, and its increasingly becoming mainstream, where every company should be thinking of the data it can collect and the value it can provide. Options like this make it easy to integrate in a Microsoft stack, and bring all the benefits of Hadoop to a wider audience.

Comments