
Semi-retirement for REST APIs with NGINX and Docker
You can’t really retire a public API, unless you want to break all your clients. But when a project winds down, you may need a cheaper runtime option for your REST API. Something that’s inexpensive to run and doesn’t have a high maintenance overhead. NGINX running on Docker is a perfect fit - lean, lightweight and reliable.
The code for a sample setup is on GitHub here: sixeyed/semi-retired-api, and if you want to try it out there’s a semi-retired-api image on the Docker Hub. Just run:
docker run -p 8080:8080 sixeyed/semi-retired-api
curl http://localhost:8080/device/12345/news
When your API is Due for Retirement
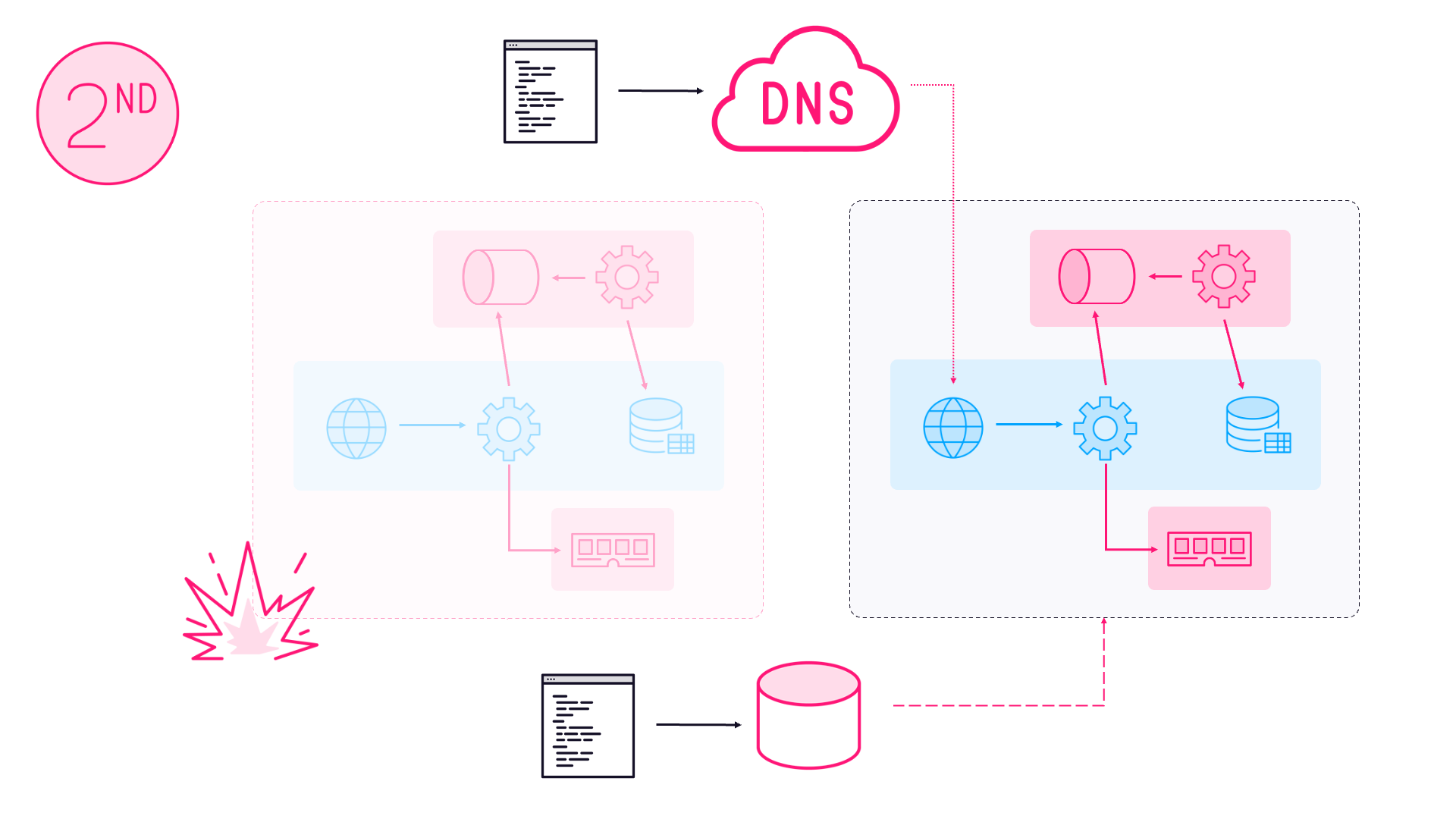
The scenario here is that you have an existing API which you’re perfectly happy with, but a business change means your API is no longer a focus - maybe the product that uses it is being discontinued - and you need to strip your running costs down as much as possible. No matter what platform your API is built on, if it’s well-designed and passes the cURL test, then it should be simple to move it into semi-retirement as a static website running on NGINX, the free open-source web server which keeps grabbing market share.
By semi-retirement I mean this: your API still meets its contract, responds correctly for all the published entry points, and supports all the existing clients.
But it effectively becomes a read-only snapshot of the data from the date it retired - read requests return a static response, and update requests return the expected response code, but don’t do anything with the client’s data.
That sounds like a drastic approach, and it is - but retiring a product is a proposition with a big impact. Businesses don’t really like paying for services to support products which are no longer generating revenue, so their preferred option may be to shut the API down altogether. But by moving to semi-retirement you can provide existing customers with a working experience, with minimal cost to the business.
As an example, for a product with over 600K active clients per month, I proposed this solution and we moved the APIs to semi-retirement with just one day’s effort. The APIs now serve all those clients from a pair of 1-core VMs on Azure. Before that, the fully-functional API was running as an Azure Web App which scaled between 12 and 16 4-core instances, so the CPU consumption has fallen from 48+ cores to just 2.
The Approach
The basic approach is to work through your API and extract static responses for all the resources you’re going to continueto support. That should be straightforward if you’ve documented your API with a tool like Apiary.
Apiary is a great tool for collaborative API design - it’s one I cover in detail in my Pluralsight course: Five Essential Tools for Building REST APIs.
After your analysis you’ll have resources which fall into one of these categories:
- generic resource, all clients receive the same response
- specific resource, different clients get different responses
- dynamic resource, response is generated for each request.
In the best case you’ll be able to support GET requests for all those resource types in the new API.
Resources which are already generic just need you to capture the JSON and save it in a text file. Resources which are specific to different clients will need some more work. Ideally you can agree that in the new restricted API, all clients will get the same response and so it becomes a generic resource. If not you’ll need to run an extract from your current API or data store to generate JSON files for each client. Dynamic resources are trickier; you’ll need to either turn them into a generic response, make proxy calls to another service, or discontinue the resource.
DML requests (PUT, POST, DELETE, PATCH) aren’t going to be supported in the new API - whether you can live with that will depend on what your API does.
Implementation in NGINX
NGINX performs superbly as a static web server, and it’s the core of the low-TCO semi-retired API. If you have a small-ish range of resources to support, then you can configure NGINX to cache them all in memory, and its responses will be super fast. Thousands of requests per second from one server is perfectly reasonable for NGINX, you could even run in production on a single node if you don’t need High Availability.
To set up NGINX, first capture all your static responses as JSON files, mirroring the URL resource path in the physical file path. I’m using www as the root folder for my responses, so the resource with URL /status/headlines is stored in /www/status/headlines.json.
I have some resources where the URL contains a query string, but they still get served by static files - so /status/updates?type=campaign will get the contents of /www/status/updates/generic/campaign.json.
You can see the folder setup for the sample API on GitHub here.
Configuring NGINX for this is very simple. We use try_files to get NGINX to lookup the source file name from the incoming request URL. That’s in the location block, where we have a couple of chained rules:
location / {
sendfile on;
tcp_nopush on;
if ($request_method = POST) {
return 201;
}
try_files $uri/$arg_type.json $uri.json $uri/empty.json =404;
}
the if means we’ll just return a 201 Created status code (with no response body) for every POST request, effectively just ditching any data the clients send in but pretending we’re still doing something with it;
try_files $uri/$arg_type.json is the first lookup rule, which takes care of requests with a query string. It will use the request URI as the folder name to look in, and use the value of the ‘type’ argument as the file name, appending the .json extension, so requests for /status/updates?type=campaign get served the contents of file /www/status/updates/generic/campaign.json
$uri.json is the next rule, which gets executed if the query string lookup doesn’t find a match. This just uses the full URI as the file path, appending .json so /status/headlines -> /www/status/headlines.json
$uri/empty.json this is a backup clause if there’s no match, telling NGINX to look for a file called empty.json using the URI as the path. This deals with unexpected query strings, so /status/updates?type=unknown -> /www/status/updates/empty.json
=404 if there are no matches, then return 404 Not Found.
The sendfile and tcp_nopush directives are simple performance tweaks. There are plenty more options for optimising NGINX performance, but even the standard setup is very fast.
There’s only one other part to request routing in the NGINX config. For some client-specific resources, we include a client identifier in the URL, but now we want to return a generic response so all clients get the same. To support that we have a rewrite rule before the location block, which strips the ID out of the URI:
rewrite ^/device/(.*)/(.*)$ /device/$2 last;
With the combination of rewrite and try_files, when NGINX gets a request for /device/12345/news it will match the file /www/device/news.json.
The full Nginx config file is on GitHub here.
Running NGINX with Docker
Running the semi-retired API on NGINX gives us a solid platform at run-time for high performance with minimal cost. But to commission a server node there are a bunch of setup steps - install NGINX, copy in the content and config, setup SSL (not in the GitHub sample, but we have SSL in the real API) etc.
We want to be able to spin new servers up and down easily and automatically, so we don’t want any manual steps. Using Docker for our NGINX API server will give us a packaged, versioned image which we can deploy on a new node in seconds.
There’s an official NGINX repository on the Docker Hub, and we can use their image as a base, so this is the Dockerfile to build our API server image (yes, this is the whole file):
FROM nginx:1.9.10
MAINTAINER Elton Stoneman <elton@sixeyed.com>
RUN mkdir -p /var/www
COPY ./www /var/www
RUN rm /etc/nginx/conf.d/default.conf
COPY ./conf/semi-retired-api.conf /etc/nginx/conf.d/
Versioning the API is still important now that it’s retired, as we will potentially want to extend it in the future. The NGINX setup is configured to return the API version in all response headers (see the x-api-version line in the NGINX config) - and we can version the Docker image to match, when we build it:
docker build -t sixeyed/semi-retired-api:1.1.3.0 .
If we change the responses, or add to the responses we provide, or extend the API to proxy POST calls we can build a new version, based off the Git tag, so the source code, container image and runtime all exhibit the same version number.
You can put the built Docker image in your own repository, or fetch the source and build it on demand when you setup a new node (either way, it can all be repeatably scripted). Then you can choose your own runtime host - Digital Ocean provide a one-click Docker app, or you can run containers on Joyent’s Elastic Container Service. More elaborate options like Docker Swarm, Mesos and the Google Container Engine are also available, but for this use case they don’t meet the low-setup, low-maintenance, low-cost requirements.
I’m running the semi-retired API on Microsoft Azure using two VMs, each one dedicated to running the NGINX Docker image. The cost is minimal, each VM runs at between 10%-15% CPU, and this has been live in production for a couple of months now with no downtime or admin required.
The VM base image is Docker on Ubuntu Server, which has Docker already installed, so it’s simple to script up creating a new node and running the Docker image.
I’m also using Docker Compose out of preference, as it effectively documents the run options for the image, and gives me the option to extend the setup easily to add more containers for more functionality. This is the Docker Compose YAML file:
semi-retired-api:
container_name: semi-retired-api
hostname: semi-retired-api
image: sixeyed/semi-retired-api:1.1.3.0
ports:
- "8080:8080"
restart: always
That specifies the source image and runtime options for the container, and the restart: always flag ensures the container gets started whenever the machine boots.
Running the API in Docker is as simple as docker-compose up -d, and then I can check the API with cURL:
elton@sc-ub-brix:~ curl http://localhost:8080/device/12345/news
{
"items":
[
{
"id": "news.item.1",
"priority": 100,
"headline":"HBase Succinctly released",
"itemUrl":"http://www.syncfusion.com/resources/techportal/details/ebooks/hbase"
},
{
"id": "news.item.2",
"priority": 150,
"headline":"HDInsight Deep Dive: Storm, HBase and Hive released",
"itemUrl":"/l/ps-hdinsight"
}
]
}
Next Steps
Actually, the whole point of this project was not to have any next steps, but to end with a simple, high performance API running with very low TCO. That’s what we have now, but there are a couple of nice-to-haves which I want to put in at some point:
add a ‘data’ container and have NGINX logs files written into the data container;
add a ‘log-uploader’ container which periodically reads the NGINX access logs from the data container and uploads them
somewhere for analysis.
If at some point we need to do something with the data we get POSTed, then I can add another container running a Node app to do that, extend the NGINX config to proxy the POST requests out to the Node container, and add a Node image to the Compose file.
Until then, this API is just enjoying semi-retirement.

Comments