
My New SRE Course: Resiliency and Automation (2025)
My New SRE Course: Resiliency and Automation 🚀
My latest Pluralsight course is out!
SRE: Resiliency and Automation
It’s the third course in the Site Reliability Engineering learning path, and it’s all about building systems that survive the chaos of production.
This course came from a simple observation: most teams think their systems are reliable because they work perfectly in test environments. But production is hostile. Pods crash, nodes fail, dependencies timeout, and cloud services have outages. The question isn’t whether these failures will happen - it’s whether your system will survive them. 💪
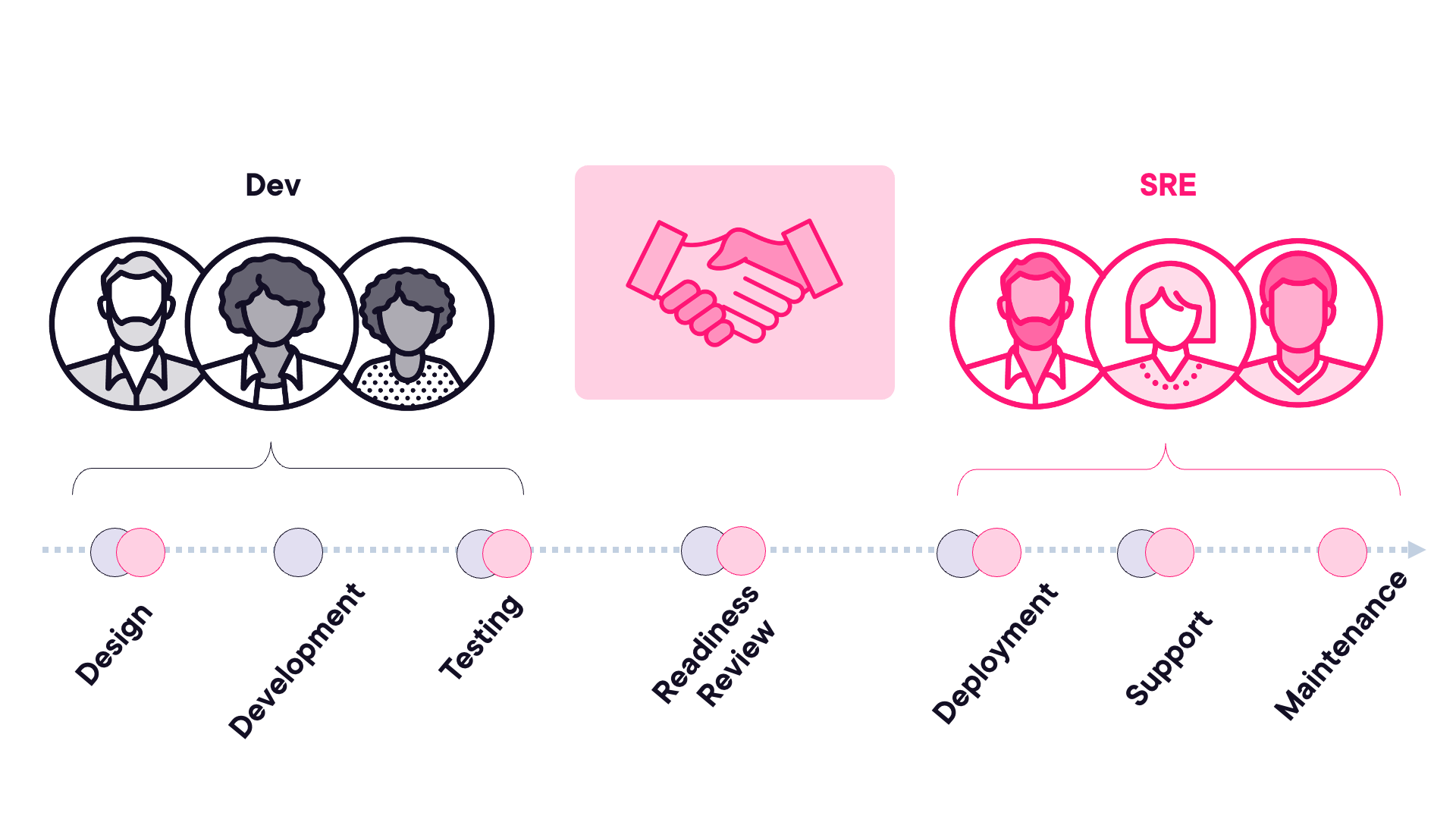
SRE Resiliency: The Story 📖
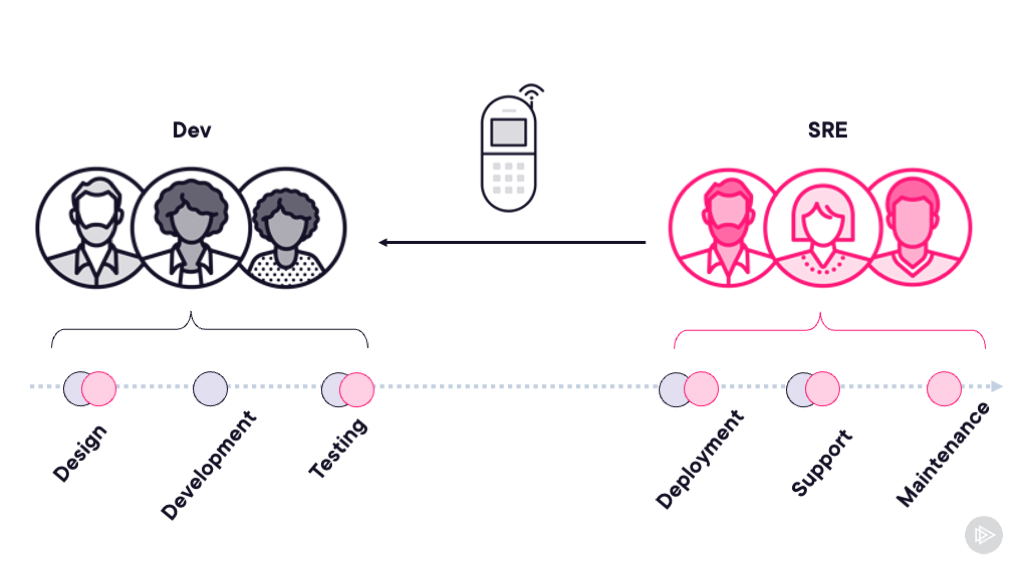
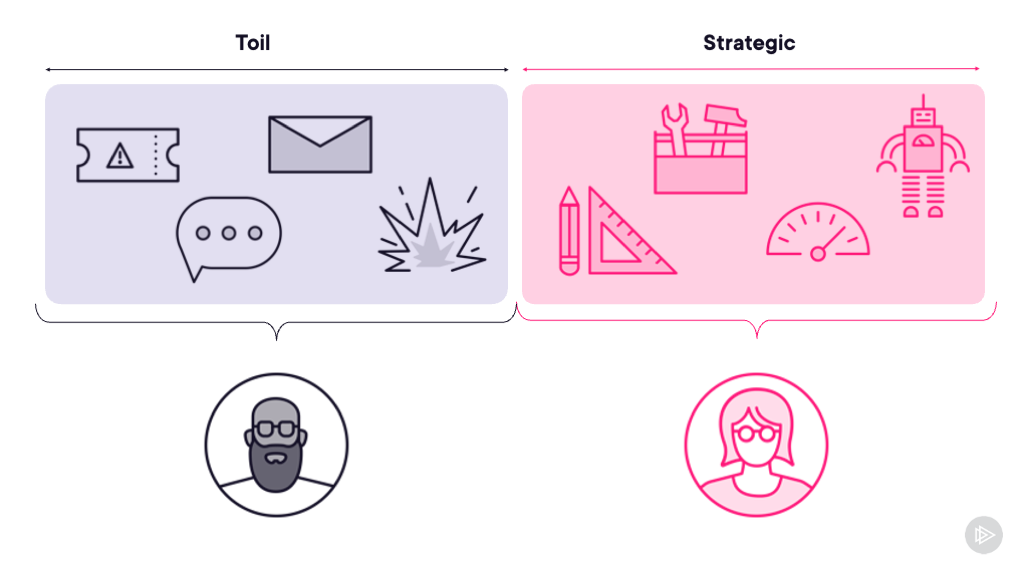
The course follows an SRE team that’s had enough. They’re handing back the pager to the development team because the application is consuming their entire toil budget with constant incidents. But this isn’t about blame - it’s about partnership. The SRE team walks the developers through exactly what needs to change before they’ll take operational responsibility back.
We use this narrative to explore the core practices that transform hope-based reliability into evidence-based confidence. You’ll follow two fictional SREs, Carlos and Keiko, as they help steer the app to production reliability. You’ll see Carlos demonstrating the problems with traditional approaches, then Keiko showing how SRE teams solve these issues at scale.
SRE Skills You’ll Master
The course covers five essential areas that every production system needs:
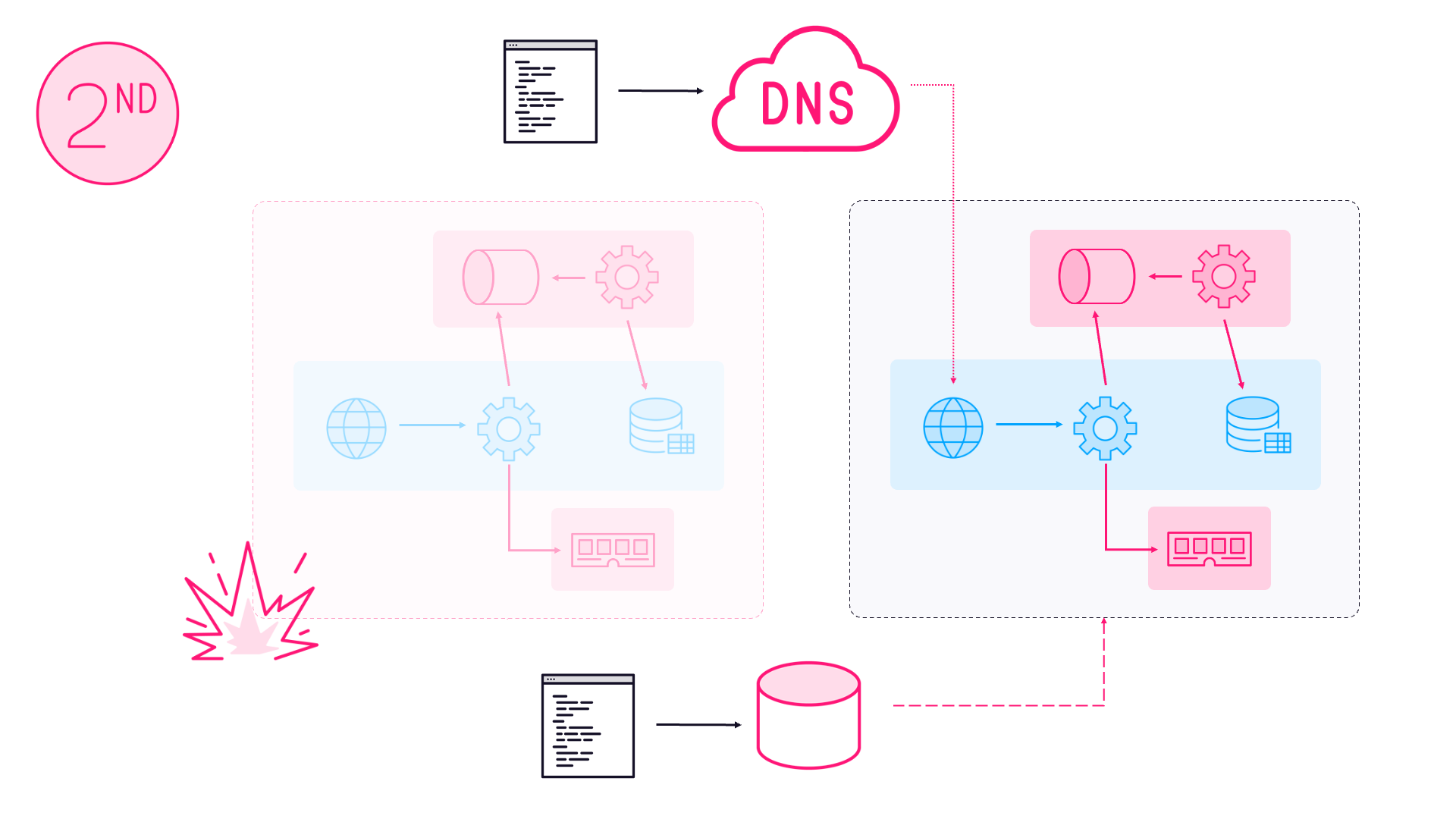
Architectural Resilience - You’ll see why synchronous architectures create operational nightmares and how patterns like distributed caching and async messaging provide the graceful degradation that production demands. We take an app that’s failing under normal load and transform it into something that maintains its SLOs.
GitOps and Automation - Manual deployments don’t scale to multiple releases per day. You’ll learn how Infrastructure as Code with Terraform, application modeling with Helm, and continuous reconciliation with ArgoCD create self-healing systems that fix themselves at 3 AM while you sleep. 😴
Capacity Planning and Autoscaling - Pre-production sizing is guesswork. The course shows how to build systems that discover their own capacity needs through horizontal pod autoscaling, cluster autoscaling, and KEDA. Start small, measure everything, and let reality drive your scaling. 📊
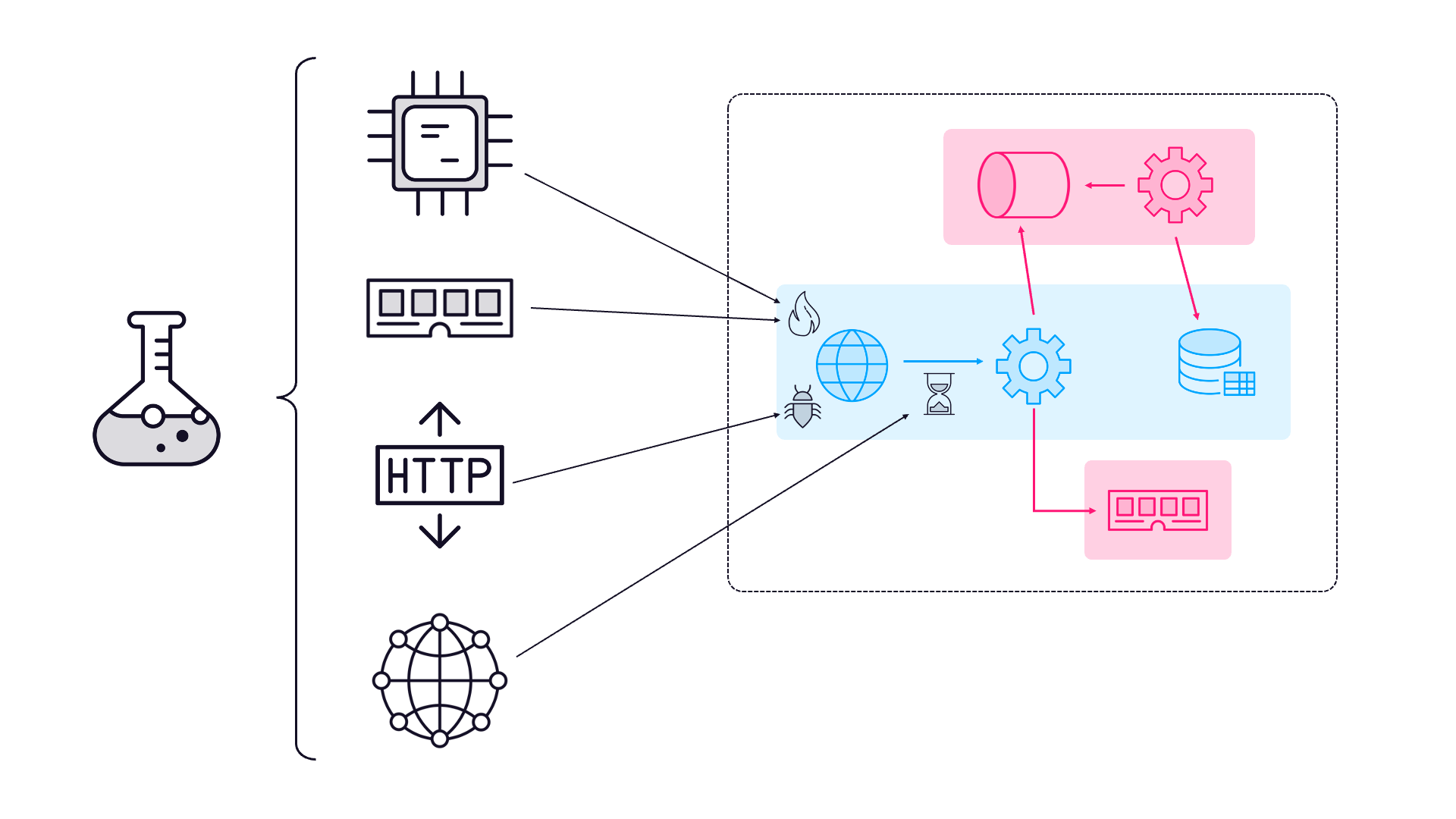
Chaos Engineering - Perfect test environments create dangerous blind spots. You’ll see how to use Chaos Mesh to deliberately break things, proving your system can handle pod failures, node crashes, and dependency outages before they happen in production. 🔨
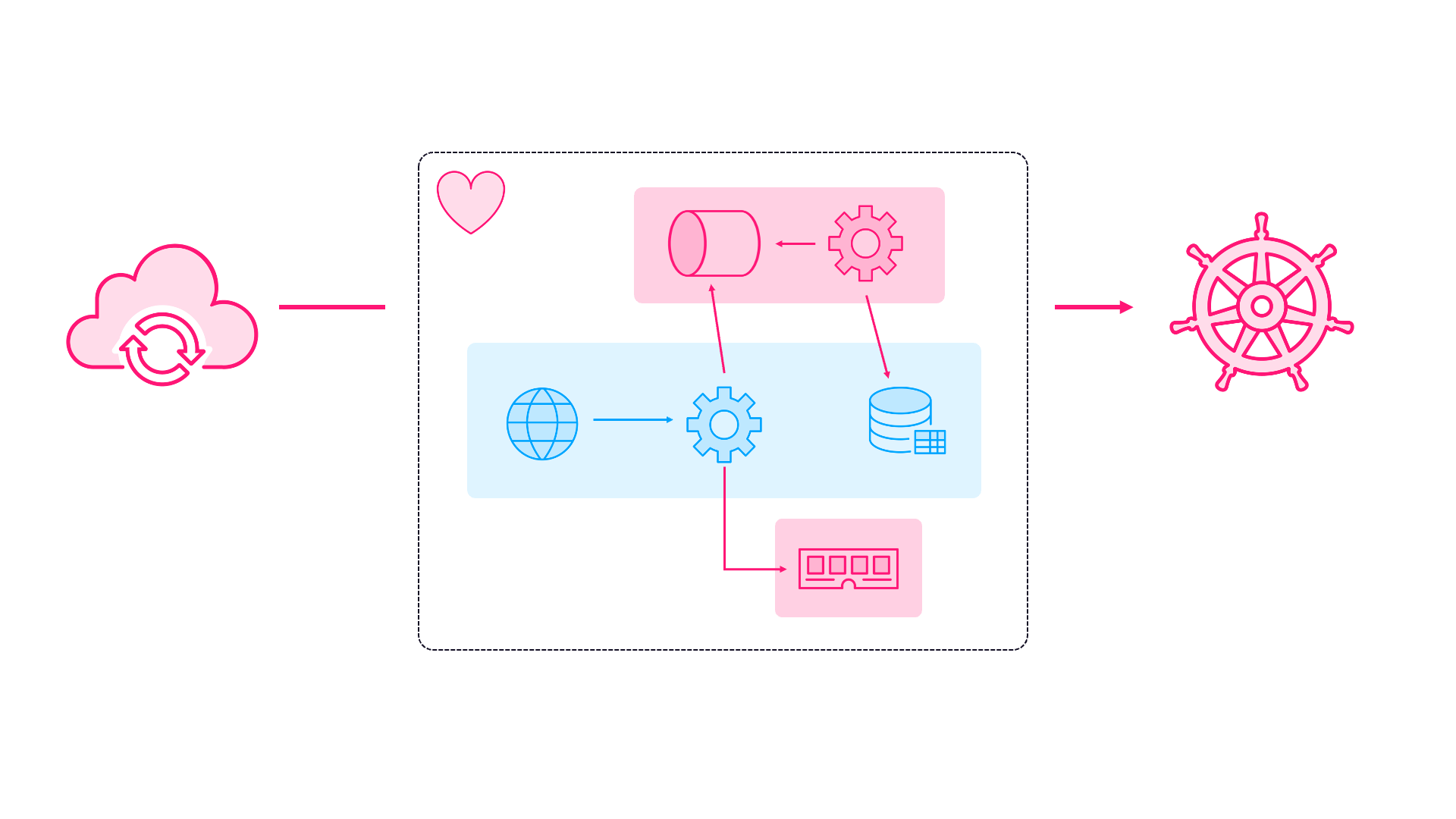
Disaster Recovery - Even the most resilient system can’t survive everything. The final module covers how SRE teams classify applications by business criticality and implement appropriate DR strategies for regional failures.
Real Problems, Real Solutions 🎯
Every demo in the course reproduces actual production problems. When you see timeouts, cascading failures, and manual deployment disasters, these aren’t theoretical examples - they’re recreations of the issues that force SRE teams to hand back the pager.
The solutions aren’t exotic either. These are the standard infrastructure patterns that emerge from running hundreds of services at scale. Distributed caching with Redis, message queuing for async processing, GitOps with ArgoCD - the tools and techniques that working SRE teams use every day.
Target Audience for SRE Professionals
This course is perfect if you’re:
- A developer working with SRE teams who wants to understand their requirements
- An operations engineer looking to move into SRE
- An architect designing systems that need to run reliably at scale
You’ll need basic knowledge of distributed systems and cloud platforms, plus an understanding of SRE fundamentals from the earlier courses in the SRE learning path. The demo application runs in Kubernetes, but you don’t need to be an expert - the principles and approaches are the key things you’ll learn here, not just the technology implementation.
The SRE Partnership Model 🤝
One thing I really wanted to emphasize in this course is that SRE isn’t about one team imposing rules on another. It’s about partnership. Development teams bring deep application knowledge and feature expertise. SRE teams bring operational experience from running systems at scale. Together, they build something neither could achieve alone.
When the SRE team hands back the pager in module one, it’s not a failure - it’s a recognition that the application needs architectural changes that only the dev team can implement. When they take it back after the improvements, both teams win. Developers get faster deployments and more autonomy. SRE teams get sustainable operations with manageable toil.
Next Steps ➡️
SRE: Resiliency and Automation is available now on Pluralsight. It’s about 90 minutes of content split across five modules, each with practical demos you can follow along with.
If you haven’t started the SRE learning path yet, begin with SRE: Concepts and Principles for the fundamentals, then move through the path to build your expertise.
The SRE approach transforms how we build and run systems. Instead of hoping things won’t break, we prove they can survive. Instead of firefighting the same issues repeatedly, we build systems that heal themselves. It’s a better way to work for everyone - developers, operators, and especially the users who depend on our services. 🎉
Happy learning!

Comments