
ARMing a Hybrid Docker Swarm: Part 4 - Reverse Proxying with Traefik
A reverse proxy quickly becomes a must-have when you’re running a container orchestrator with more than a couple of services. Network ports are single-occupancy resources, you can’t have multiple processes listening on the same port, whether they’re different apps or different containers.
You can’t run different web apps in containers all listening on port 80. Docker lets you map ports instead, so if the app inside a container expects traffic on port 80 you can actually publish to a different port on the host - say 8080 - and Docker will receive traffic on port 8080 and send it to port 80 in the container.
That doesn’t work for public-facing services though. Non-standard ports are only suitable for private or test environments. Public HTTP clients expect to use port 80, and HTTPS to use port 443. That’s where a reverse proxy comes in.
You run the proxy in a container, publishing ports 80 and 443. All your other services run in containers, but they don’t publish any ports - only the reverse proxy is accessible. It’s the single entrypoint for all your services, and it has rules to relay incoming requests to other containers using private Docker networks.
Reverse Proxy Containers
A reverse proxy is just an HTTP server which doesn’t have any of its own content, but fetches content from other servers - containers in this case. You define rules to link the incoming request to the target service. The HTTP host header is the typical example. The reverse proxy can load content for blog.sixeyed.com from the container called blog, and api.sixeyed.com from the container called api.
Reverse proxies can do a lot more than route traffic. They can load-balance requests across containers, or use sticky sessions to keep serving known users from the same container. They can cache responses to reduce the load on your web apps, they can apply SSL so you keep security concerns out of your app code, and they can modify responses, stripping HTTP headers or adding new ones.
Nginx and HAProxy are very popular options for running a reverse proxy, but they aren’t explicitly container-aware. They need to be configured with a static list of rules where the targets are container names or service names. Traefik is different - its all about containers. You run Traefik in a container, and it accesses the Docker API and builds it own rules based on labels you apply to containers or swarm services.
I’ll use Traefik to proxy my other applications, based on domain names I have specified in Dnsmasq. For example jenkins.athome.ga is configured as a CNAME for managers.swarm.sixeyed which contains A records for all the swarm manager IPs. Requests for jenkins.athome.ga will be routed to a Traefik container running on one of the managers, and it will proxy content from Jenkins running in a container on one of the workers:
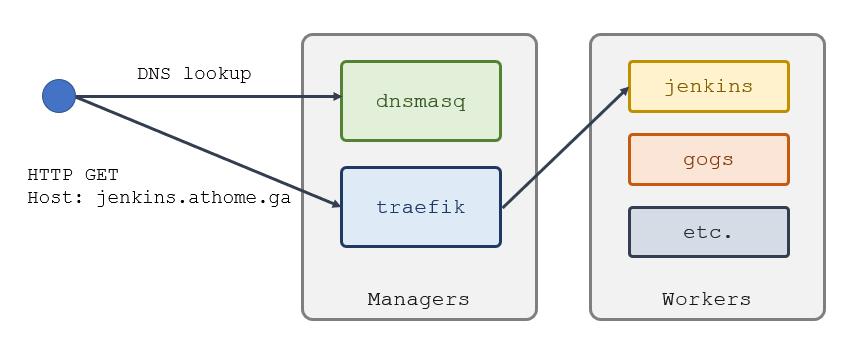
Configuring Traefik with Docker Swarm
The Traefik setup is very simple - the docs are excellent and tell you exactly how to configure Traefik to run in Docker Swarm. The Traefik team already publish a multi-arch image with an ARM64 variant, so I can use their image directly:
> docker manifest inspect traefik:1.7.9
...
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 739,
"digest": "sha256:917444e807edd21cb02a979e7d805391c5f6edfc3c02...",
"platform": {
"architecture": "arm64",
"os": "linux",
"variant": "v8"
}
}
Traefik has a very similar runtime profile to the DNS service I walked through in Part 3 - Name Resolution with Dnsmasq. It has high availability requirements and low compute requirements, so I’m also running it as a global service on my manager nodes.
If you’re flinching at these workloads running on the managers, I promise it will only be Traefik and Dnsmasq, and that leaves plenty of RAM on the manager nodes.
Here’s my Docker Compose specification for running Traefik. Nothing special - the deployment section specifies the placement and resource constraints:
deploy:
mode: global
resources:
limits:
cpus: '0.50'
memory: 250M
placement:
constraints:
- node.platform.os == linux
- node.role == manager
The startup command tells Traefik it’s running in Docker Swarm and it should connect to the Docker API using the local pipe, so each container connects to the Docker engine where it is running.
Traefik queries the Docker API looking for labels which configure front-end routing rules. As services and containers come and go in the swarm, Traefik keeps its routing list up-to-date.
You can see that routing list in Traefik’s admin Web UI, which is enabled with the --api flag in the startup command. My compose file includes Traefik routing labels for Traefik itself, the host name proxy.athome.ga gets served from port 8080:
labels:
- "traefik.frontend.rule=Host:proxy.athome.ga"
- "traefik.port=8080"
- "traefik.docker.network=frontend"
Running Traefik as a Docker Swarm Service
Deploying the proxy is just a case of deploying the stack:
docker stack deploy -c .\traefik.yml proxy
Now I have DNS resolution with Dnsmasq and reverse proxying with Traefik, which gives a friendly DNS name to a whole bunch of services:
> docker stack ls
NAME SERVICES ORCHESTRATOR
blog-dev 1 Swarm
dns 1 Swarm
gogs 1 Swarm
jenkins 1 Swarm
nextcloud 1 Swarm
proxy 1 Swarm
registry 1 Swarm
samba 1 Swarm
squeezebox 1 Swarm
unifi 1 Swarm
At the proxy address, I see the routing rules Traefik has built. “Front-ends” are the HTTP request configuration Traefik is looking for, and “back-ends” are the containers where requests get proxied from:
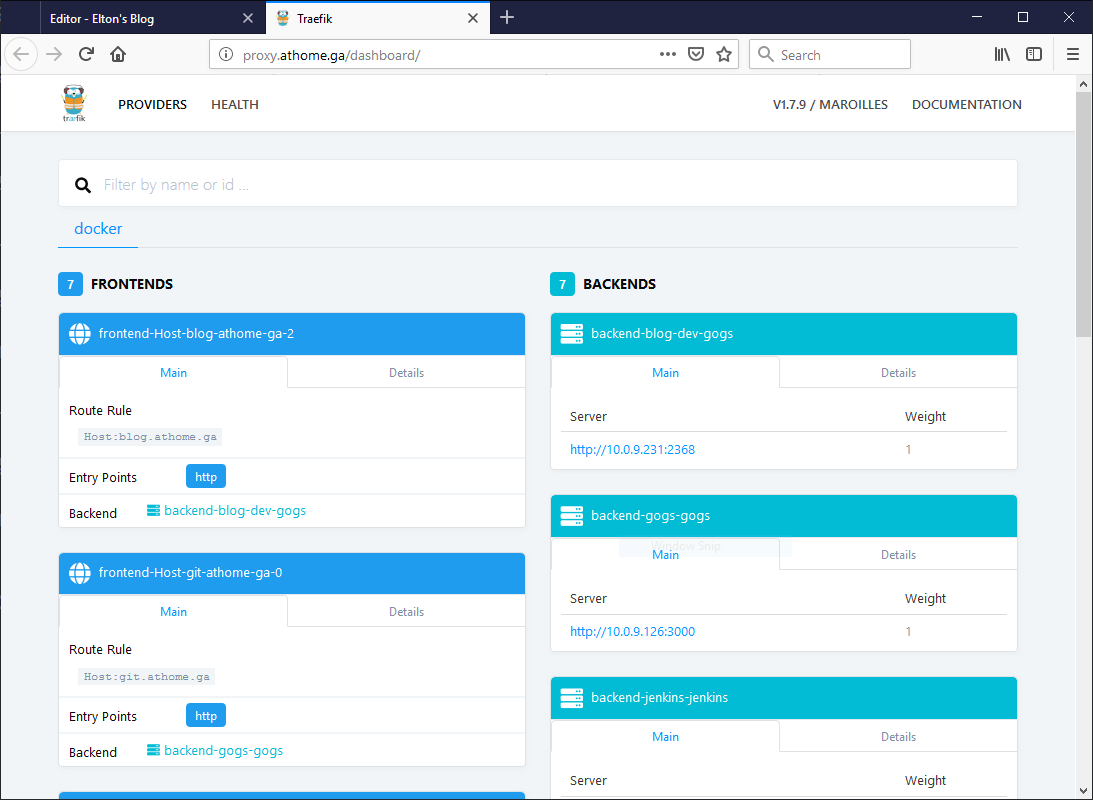
I’m all set with the core services in my cluster now - I can run apps anywhere on the workers and access them with a friendly DNS name and a standard HTTP port.
But all the other services I want to run are stateful, which means I need a shared storage solution across the swarm. There are a few options for that, and in the next article I’ll walk through my choice to set up GlusterFS.
Articles which may appear in this series:
Part 3 - Name Resolution with Dnsmasq
Part 4 - Reverse Proxying with Traefik
Part 5 - Distributed Storage with GlusterFS
Part 5 - CI/CD with Gogs, Jenkins & Registry
Part 6 - Building and Pushing Multi-Arch Images

Comments