
HDInsight Deep Dive: Storm, HBase and Hive
My latest Pluralsight course is out now:
It’s an in-depth look at the Azure Big Data offerings that went live this year - HDInsight clusters running Storm, HBase and Hive. Those are three tried-and-trusted Big Data technologies from Apache, which you can run in the Azure cloud on a pay-as-you-go compute model.
Storm is a distributed compute platform which works well as an event processor; HBase is a NoSQL database used for real-time access with huge quantities of data, and Hive is a data warehouse that can run over HBase and Hadoop data with a SQL-like interface.
Who’s the course for?
This is an Intermediate level course that starts with the basics on all the technologies, and then goes into a deep dive.
You’ll learn all you need to know about Azure, HDInsight, Storm, HBase and Hive to deliver high-quality, high-value solutions.
The course uses C#, .NET and Visual Studio, so you’ll benefit if you have some experience there, but no prior knowledge of HDInsight or Big Data is required.
What does the course demonstrate?
No word counts!
No Web server logs!
In the course I demonstrate building a useful, complex solution where Big Data technologies are a good fit, reducing the amount of code you need to write while providing a solution capable of handling massive scale.
The demo solution is an example of how you can build a high-scale transactional solution leveraging the Hadoop stack. And the problem is one which is well suited to having occasional compute - firing up the clusters when you need to process data, and spinning them down afterwards.
That’s a crucial approach for minimizing spend in the cloud, and I show how to do that and provide access to key data even when the clusters are deleted.
The demo code for the course is a race timing solution where the timers on the course send events to Azure Event Hubs:
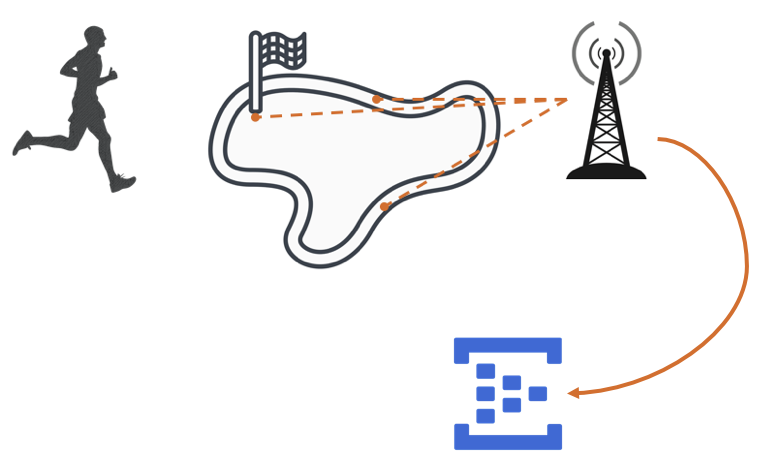
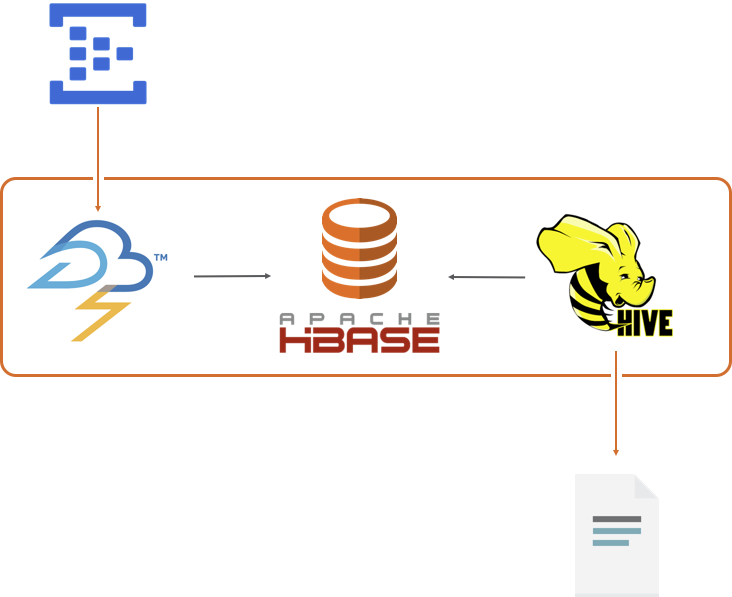
The events are pulled by a Storm application, which saves the raw data in HBase and also stores and calculates and saves interim results.
Timing events may be received out of order though, so the interim results could be incorrect. When the race is complete I use Hive to calculate the final results from the raw timing event data, and write it out to HDFS as an Azure blob, which is available whether the HDInsight cluster is running or not.
How deep do you dive?
For each technology there’s a functional module where I introduce the stack and build out the race timing solution. Then there’s a Deep Dive module for each technology, which details how it works and how to get the best from it:
Storm Deep Dive - covers performance tuning Storm topologies; how applications are distributed in HDInsight; implementing guaranteed messaging; unit and integration testing Storm .NET solutions
HBase Deep Dive - what the servers in the cluster do; region splits and pre-splitting regions; load balancing Stargate with Nginx; integration testing HBase .NET solutions using a Docker container
Hive Deep Dive - HiveQL execution plans; monitoring jobs with YARN; filter push-down for HBase tables; submitting jobs with PowerShell; accessing Hive from C# with ODBC
Where does this course fit?
HDInsight Deep Dive complements my previous Big Data course for Pluralsight - Real World Big Data in Azure. That takes a first-principles approach to Big Data and looks at building custom code to process it.
Often that works well for your first Big Data project(s), but you can find the amount of code you need to maintain and the stack you have to monitor can slow you down.
Leveraging more tools from the Hadoop ecosystem, especially where they run as managed HDInsight clusters on Azure, can make a compelling case for implementing a more streamlined Big Data solution, which this course shows you how to do.
Comments