
Learn Docker in a Month: your week 4 guide
The YouTube series of my book Learn Docker in a Month of Lunches is all done! The final five episodes dig into some more advanced topics which are essential in your container journey, with the theme: getting your containers ready for production.
The whole series is on the Learn Docker in a Month of Lunches playlist and you can find out about the book at the DIAMOL homepage
Episode 16: Optimizing your Docker images for size, speed and security
It’s easy to get started with Docker, packaging your apps into images using basic Dockerfiles. But you really need a good understanding of the best practices to safe yourself from trouble later on.
Docker images are composed of multiple layers, and layers can be cached and shared between images. That’s what makes container images so lightweight - similar apps can share all the common layers. Knowing how the cache works and how to make the best use of it speeds up your build times and reduces image size.
Smaller images mean faster network transfers and less disk usage, but they have a bigger impact too. The space you save is typically from removing software your apps don’t actually need to run, and that reduces the attack surface for your application in production - here’s how optimization counts:
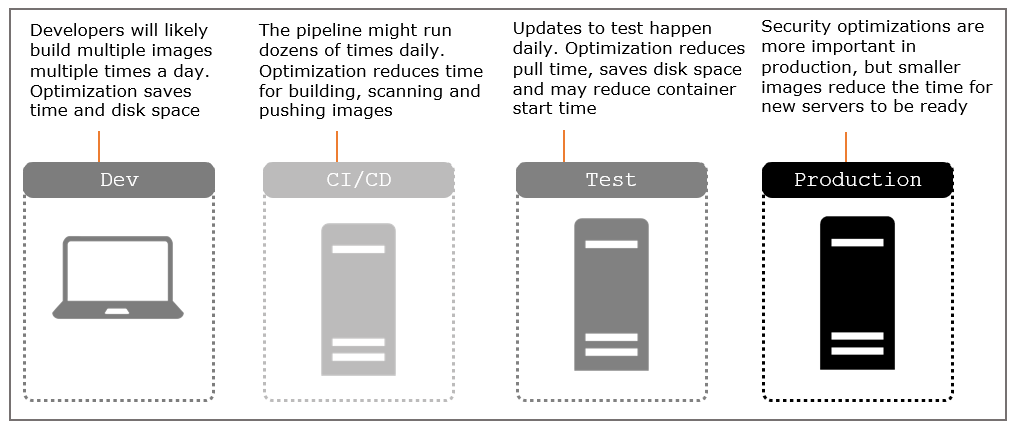
This episode covers all those with recommendations for using multi-stage Dockerfiles to optimize your builds and your runtime images.
Episode 17: Application configuration management in containers
Your container images should be generic - you should run the same image in every environment. The image is the packaging format and one of the main advantages of Docker is that you can be certain the app you deploy to production will work in the same way as the test environment, because it has the exact same set of binaries in the image.
Images are built in the CI process and then deployed by running containers from the image in the test environments and then onto production. Every environment uses the same image, so to allow for different setups in each environment your application needs to be able to read configuration from the container environment.
Docker creates that environment and you can set configuration using environment variables or files. Your application needs to look for settings in known locations and then you can provide those settings in your Dockerfile and container run commands. The typical approach is to use a hierarchy of config sources, which can be set by the container platform and read by the app:
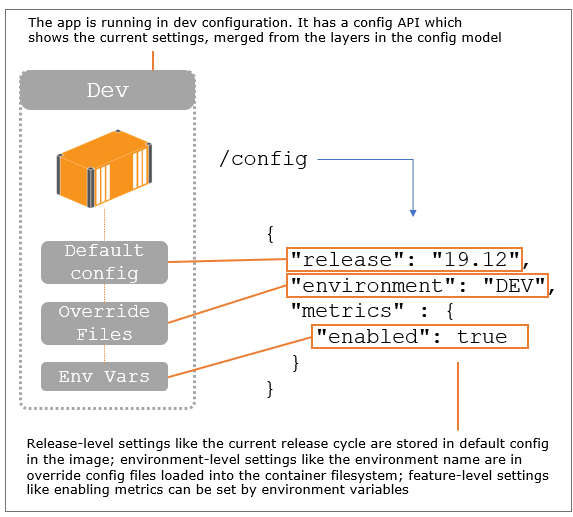
Episode 17 walks through different variations of that config hierarchy in Docker, using examples in Node.js with node-config, Go with Viper and the standard config systems in .NET Core and Java Spring Boot.
Episode 18: Writing and managing application logs with Docker
Docker adds a consistent management layer to all your apps - you don’t need to know what tech stack they use or how they’re configured to know that you start them with docker run and you can monitor them with docker top and docker logs. For that to work, your app needs to fit with the conventions Docker expects.
Container logs are collected from the standard output and standard error streams of the startup process (the one in the CMD or ENTRYPOINT instruction). Modern app platforms run as foreground processes which fits neatly with Docker’s expectations. Older apps might write to a different log sink which means you need to relay logs from a file (or other source) to standard out.
You can do that in your Dockerfile without any changes to your application which means old and new apps behave in the same way when they’re running in containers:
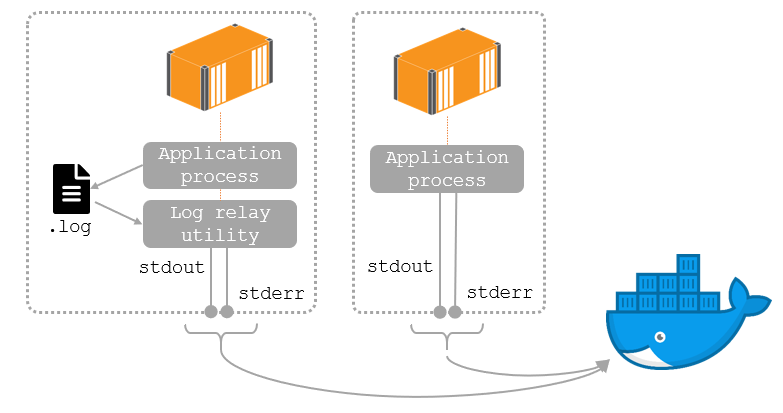
This episode shows you how to get logs out from your apps into containers, and then collect those logs from Docker and forward them to a central system for storage and searching - using the EFK stack (Elasticsearch, Fluentd and Kibana).
Episode 19: Controlling HTTP traffic to containers with a reverse proxy
The series ends with a couple of more in-depth topics which will help you understand how your application architecture might look as you migrate more apps to containers. The first is managing network traffic using a reverse proxy.
A reverse proxy runs in a container and publishes ports to Docker. It’s the only publicly-accessible component, all your other containers are internal and can only be reached by other containers on the same Docker network. The reverse proxy receives all incoming traffic and fetches the content from the application container:
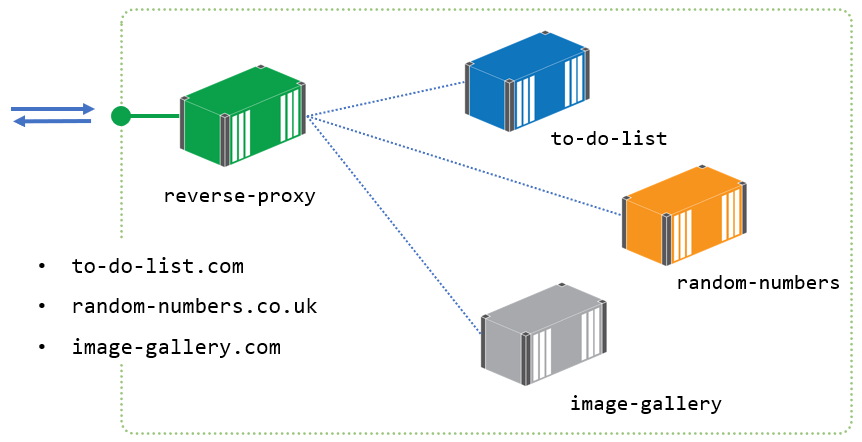
Reverse proxies can do a lot of work for you - SSL termination, response caching, sticky sessions - and we see them all in this episode. The demos use two of the most popular technologies in this space, Nginx and Traefik and helps you to evaluate them.
Episode 20: Asynchronous communication with a message queue
This is one of my favourite topics. Message queues let components of your apps communicate asynchronously - decoupling the consumer and the service. It’s a great way to add reliability and scale to your architecture, but it used to be complex and expensive before Docker.
Now you can run an enterprise-grade message queue like NATS in a container with minimal effort and start moving your apps to a modern event-driven approach. With a message queue in place you can have multiple features triggering in response to events being created:
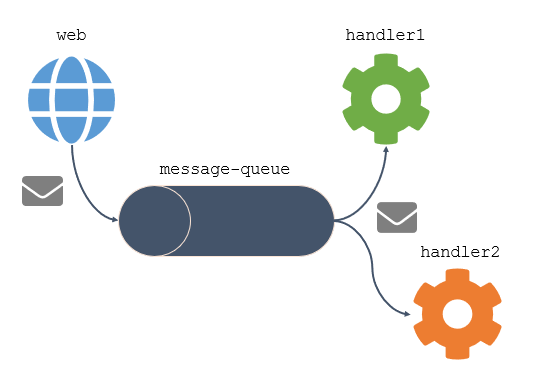
This is an enabler for all sorts of patterns, and episode 20 walks you through a few of them: decoupling a web app from the database to increase scale and adding new features without changing the existing application.
This episode also covers Chapter 22 of the book, with some tips on helping you to gain adoption for Docker in your organization.
And next… Elton’s Container Show (ECS)
That’s all for the book serialization. I’ll do the same thing when my new book Learn Kubernetes in a Month of Lunches gets released - it’s in the finishing stages now and you can read all the chapters online.
In the meantime I have a new YouTube show all about containers called… Elton’s Container Show. It runs once a week and each month I’ll focus on a particular topic. The first topic is Windows containers and then I’ll move on to orchestration.
You’ll find all the info here at https://eltons.show and the first episode is ECS-W1: We Need to Talk About Windows Containers.
Hope to see you there :)
Comments