
LEARN DOCKER IN ONE MONTH! Your week 3 guide.
My YouTube series to help you learn Docker continued this week with five more episodes. The theme for the week is running at scale with a container orchestrator.
You can find all the episodes on the Learn Docker in a Month of Lunches playlist, and more details about the book at https://diamol.net
Episode 11: Understanding Orchestration - Docker Swarm and Kubernetes
Orchestration is how you run containers at scale in a production environment. You join together a bunch of servers which have Docker running - that’s called the cluster. Then you install orchestration software to manage containers for you. When you deploy an application you send a description of the desired state of your app to the cluster. The orchestrator creates containers to run your app and makes sure they keep running even if there are problems with individual servers.
The most common container orchestrators are Docker Swarm and Kubernetes. They have very different ways of modelling your applications and different feature sets, but they work in broadly the same way. They manage the containers running on the server and they expose an API endpoint you use for deployment and administration:
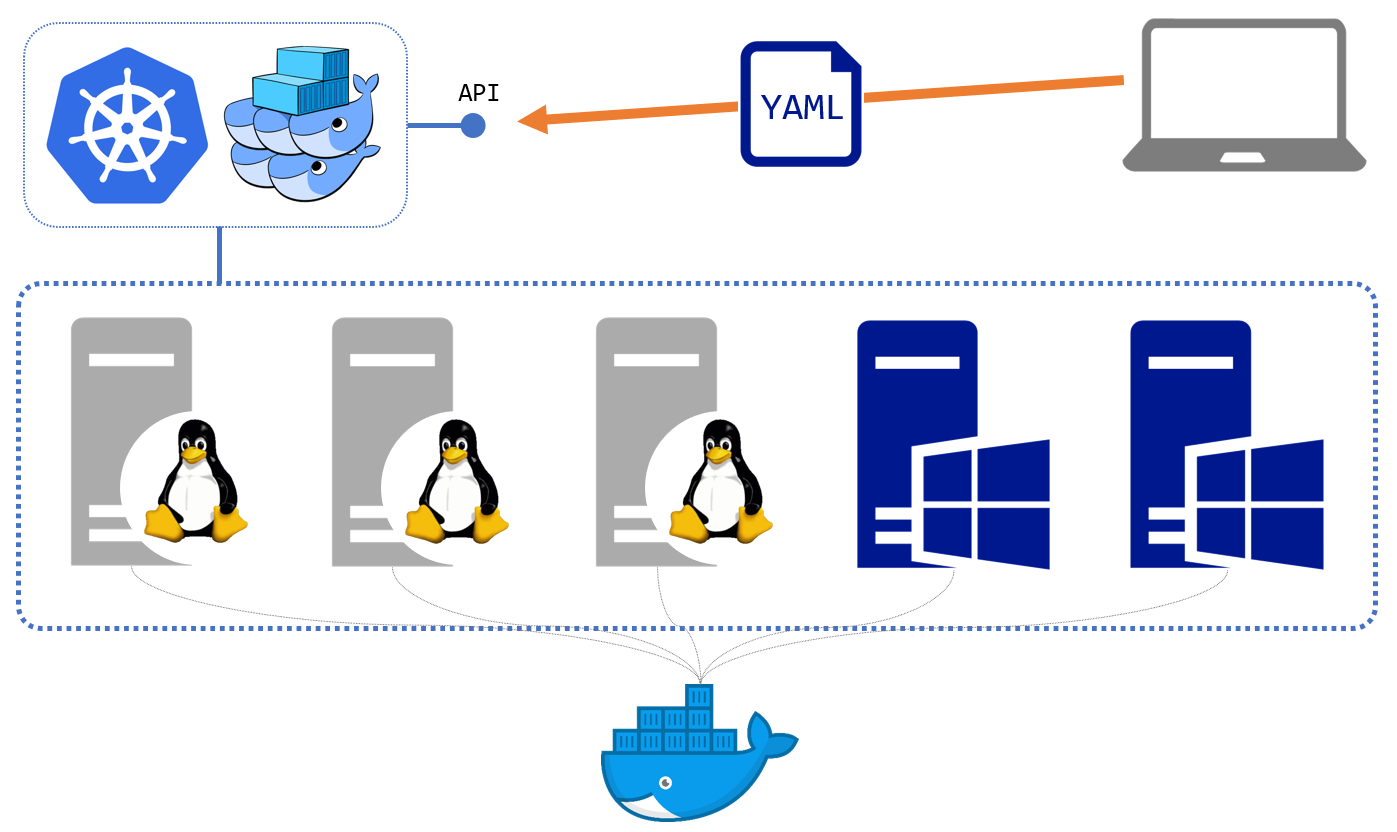
This episode walks through the main features of orchestration, like high availability and scale, and the abstractions they provide for compute, networking and storage. The exercises all use Docker Swarm which is very simple to set up - it’s a one-line command once you have Docker installed:
docker swarm init
And that’s it :)
Swarm uses the Docker Compose specification to model applications so it’s very simple to get started. In the episode I compare Swarm and Kubernetes and suggest starting with Swarm - even if you plan to use Kubernetes some day. The learning curve for Swarm is much smoother than Kubernetes, and once you know Swarm you’ll have a good understanding of orchestration which will help you learn Kubernetes (although you’ll need a good book to help you, something like Learn Kubernetes in a Month of Lunches).
Episode 12: Deploying Distributed Apps as Stacks in Docker Swarm
Container orchestrators use a distributed database to store application definitions, and your deployments can include custom data for your application - which you can use for configuration settings. That lets you use the same container images which have passed all your automated and manual tests in your production environment, but with production settings applied.
Promoting the same container image up through environments is how you guarantee your production deployment is using the exact same binaries you’ve approved in testing. The image contains the whole application stack so there’s no danger of the deployment failing on missing dependencies or version mismatches.
To support different behaviour in production you create your config objects in the cluster and reference them in your application manifest (the YAML file which is in Docker Compose format if you use Swarm, or Kubernetes’ own format). When the orchestrator creates a container which references a config object it surfaces the content of the object as a files in the container filesystem - as in this sample Docker Swarm manifest:
todo-web:
image: diamol/ch06-todo-list
ports:
- 8080:80
configs:
- source: todo-list-config
target: /app/config/config.json
Config objects are used for app configuration and secrets are used in the same way, but for sensitive data. The episode shows you how to use them and includes other considerations for deploying apps in Swarm mode - including setting compute limits on the containers and persisting data in volumes.
Episode 13: Automating Releases with Upgrades and Rollbacks
One of the goals of orchestration is to have the cluster manage the application for you, and that includes providing zero-downtime updates. Swarm and Kubernetes both provide automated rollouts when you upgrade your applications. The containers running your app are gradually updated, with the ones running the old version replaced with new containers running the new version.
During the rollout the new containers are monitored to make sure they’re healthy. If there are any issues then the rollout can be stopped or automatically rolled back to the previous version. The episode walks through several updates and rollbacks, demonstrating all the different configurations you can apply to control the process. This is the overall process you’ll see when you watch:
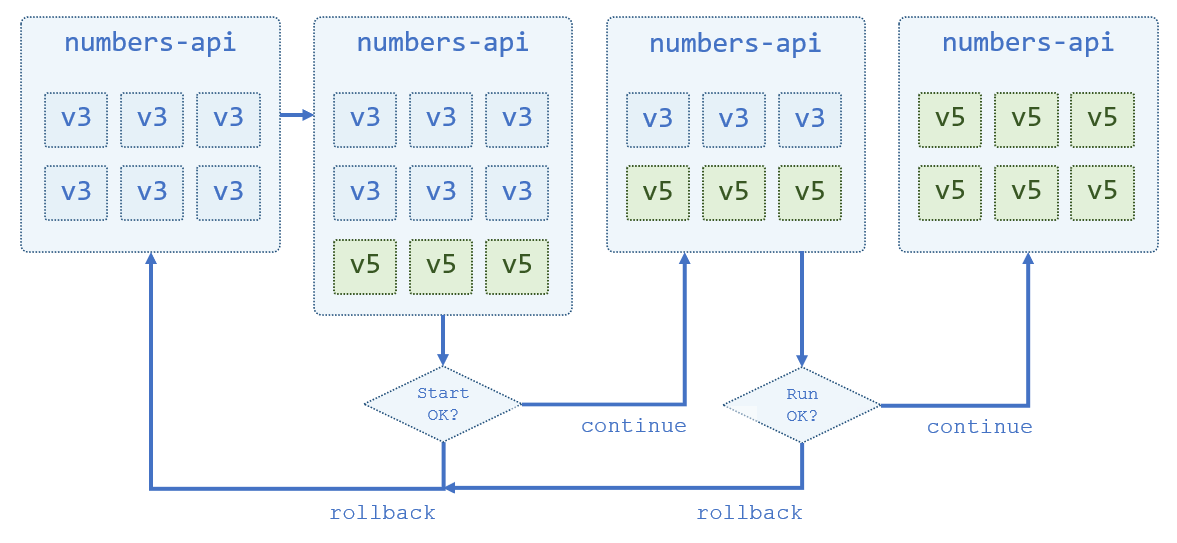
You can configure all the aspects of the rollout - how many containers are started, whether the new ones are started first or the old ones are removed first, how long to monitor the health of new containers and what to do if they’re not healthy. You need a pretty good understanding of all the options so you can plan your rollouts and know how they’ll behave if there’s a problem.
Episode 14: Configuring Docker for Secure Remote Access and CI/CD
The Docker command line doesn’t do much by itself - it just sends instructions to the Docker API which is running on your machine. The API is part of the Docker Engine, which is what runs and manages containers. You can expose the API to make it remotely available, which means you can manage your Docker servers in the cloud from the Docker command line running on your laptop.
There are good and bad ways to expose the API, and this episode covers the different approaches - including secure access using SSH and TLS. You’ll also learn how to use remote machines as Docker Contexts so you can easily apply your credentials and switch between machines with commands like this:
# create a context using TLS certs:
docker context create x--docker "host=tcp://x,ca=/certs/ca.pem,cert=/certs/client-cert.pem,key=/certs/client-key.pem"
# for SSH it would be:
docker context create y --docker "host=ssh://user@y
# connect:
docker context use x
# now this will list containers running on server x:
docker ps
You’ll also see why using environment variables is preferable to docker context use…
Remote access is how you enable the Continuous Deployment part of the CI/CD pipeline. This episode uses Play with Docker, an online Docker playground, as a remote target for a deployment running in Jenkins on a local container. It’s a pretty slick exercise (if I say so myself), which you can try out in chapter 15 of Learn Docker in a Month of Lunches.
This feature-packed episode ends with an overview of the access model in Docker, and explains why you need to carefully control who has access to your machines.
Episode 15: Building Docker Images that Run Anywhere: Linux, Windows, Intel & Arm
Every exercise in the book uses Docker images which are built to run on any of the main computing architectures - Windows and Linux operating systems, Intel and Arm CPUs - so you can follow along whatever computer you’re using. In this episode you’ll find out how that works, with multi-architecture images. A multi-arch image is effectively one image tag which has multiple variants:
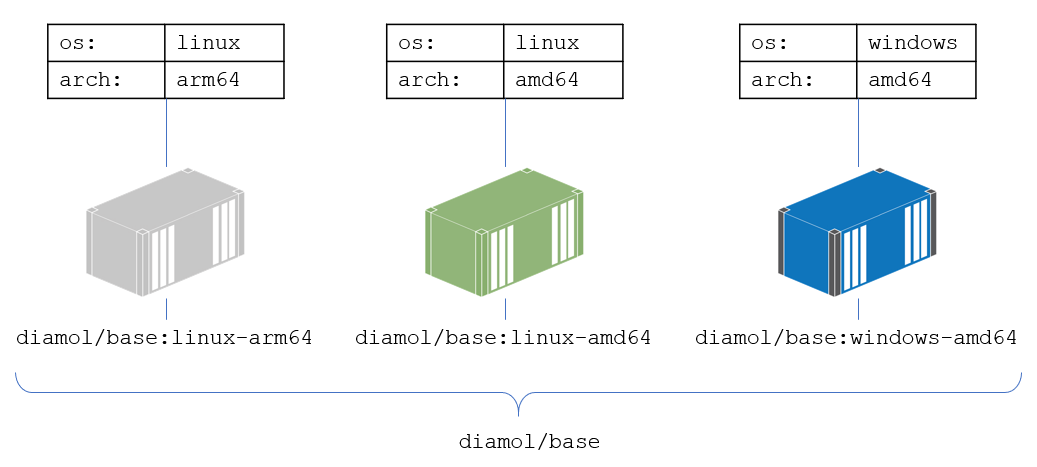
There are two ways to create multi-arch images: build and push all the variants yourself and then push a manifest to the registry which describes the variants, or have the new Docker buildx plugin do it all for you. The episode covers both options with lots of examples and shows you the benefits and limitations of each.
You’ll also learn why multi-arch images are important (example: you could cut your cloud bills almost in half by running containers on Arm instead of Intel on AWS), and the Dockerfile best practices for supporting multi-arch builds.
Coming next
Week 3 covered orchestration and some best practices for production deployments. Week 4 is the final week and the theme is production readiness. You’ll learn everything you need to take a Docker proof-of-concept project into production, including optimizing your images, managing app configuration and logging, and controlling traffic to your application with a reverse proxy.
The live stream is running through September 2020 and kicks off on my YouTube channel weekdays at 19:00 UTC. The episodes are available to watch on demand as soon as the session ends.
Hope you can join me on the final leg of your journey to learn Docker in one month :)
Comments