
Learn Docker in ONE MONTH. Your guide to week 2.
I’ve added five more episodes to my YouTube series Learn Docker in a Month of Lunches. You can find the overview at https://diamol.net and the theme for week 2 is:
Running distributed applications in containers
This follows a tried-and-trusted path for learning Docker which I’ve used for workshops and training sessions over many years. Week 1 is all about getting used to Docker and the key container concepts. Week 2 is about understanding what Docker enables you to do, focusing on multi-container apps with Docker Compose.
Episode 6: Running multi-container apps with Docker Compose
Docker Compose is a tool for modelling and managing containers. You model your apps in a YAML file and use the Compose command line to start and stop the whole app or individual components.
We start with a nice simple docker-compose.yml file which models a single container plugged into a Docker network called nat:
version: '3.7'
services:
todo-web:
image: diamol/ch06-todo-list
ports:
- "8020:80"
networks:
- app-net
networks:
app-net:
external:
name: nat
The services section defines a single component called todo-web which will run in a container. The configuration for the service includes the container image to use, the ports to publish and the Docker network to connect to.
Docker Compose files effectively capture all the options you would put in a docker run command, but using a declarative approach. When you deploy apps with Compose it uses the spec in the YAML file as the desired state. It looks at the current state of what’s running in Docker and creates/updates/removes objects (like containers or networks) to get to the desired state.
Here’s how to run that app with Docker Compose:
# in this example the network needs to exist first:
docker network create nat
# compose will create the container:
docker-compose up
In the episode you’ll see how to build on that, defining distributed apps which run across multiple containers in a single Compose file and exploring the commands to manage them.
You’ll also learn how you can inject configuration settings into containerized apps using Compose, and you’ll understand the limitations of what Compose can do.
Episode 7: Supporting reliability with health checks and dependency checks
Running your apps in containers unlocks new possibilities, like scaling up and down on demand and spreading your workload across a highly-available cluster of machines. But a distributed architecture introduces new failure modes too, like slow connections and timeouts from unresponsive services.
Docker lets you build reliability into your container images so the platform you use can understand if your applications are healthy and take corrective action if they’re not. That gets you on the path to self-healing applications , which manage themselves through transient failures.
The first part of this is the Docker HEALTHCHECK instruction which lets you configure Docker to test if your application inside the container is healthy - here’s the simplest example in a Dockerfile:
# builder stage omitted in this snippet
FROM diamol/dotnet-aspnet
ENTRYPOINT ["dotnet", "/app/Numbers.Api.dll"]
HEALTHCHECK CMD curl --fail http://localhost/health
WORKDIR /app
COPY --from=builder /out/ .
This is a basic example which uses curl - I’ve already written about why it’s a bad idea to use curl for container healthchecks and you’ll see in this episode the better practice of using the application runtime for your healthcheck.
When a container image has a healthcheck specified, Docker runs the command inside the container to see if the application is healthy. If it’s unhealthy for a number of successive checks (the default is three) the Docker API raises an event. Then the container platform can take corrective action like restarting the container or removing it and replacing it.
This episode also covers dependency checks, which you can use in your CMD or ENTRYPOINT instruction to verify your app has all the dependencies it needs before it starts. This is useful in scenarios where components can’t do anything useful if they’re missing dependencies - but without the check it the container would start and it would look as if everything was OK.
Episode 8: Adding observability with containerized monitoring
Healthchecks and dependency checks get you a good way to reliability, but you also need to see what’s going on inside your containers for situations where things go wrong in unexpected ways.
One of the big issues for ops teams moving from VMs to containers is going from a fairly static environment with a known set of machines to monitor, to a dynamic environment where containers appear and disappear all the time.
This episode introduces the typical monitoring stack for containerized apps using Prometheus. In this architecture all your containers expose metrics in an HTTP endpoint, as do your Docker servers. Prometheus runs in a container too and it collects those metrics and stores them in a time-series database.
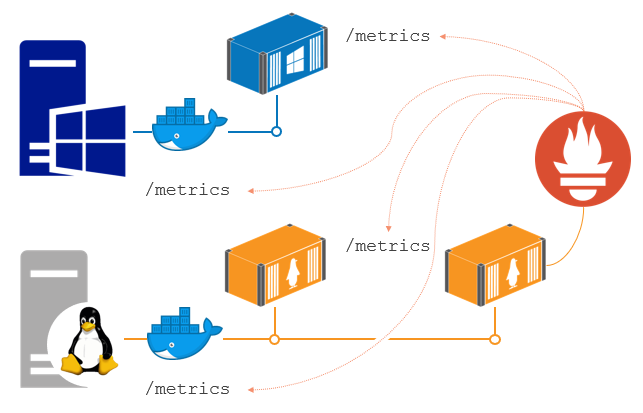
You need to add metrics to your app using a Prometheus client library, which will provide a set of runtime metrics (like memory and CPU usage) for free. The client library also gives you a simple way to capture your own metrics.
The demo apps for this module have components in .NET, Go, Java and Node.js so you can see how to use client libraries in different languages and wire them up to Prometheus.
You’ll learn how to run a monitoring solution in containers alongside your application, all modelled in Docker Compose. One of the great benefits of containerized monitoring is that you can run the same tools in every environment - so developers can use the same Grafana dashboard that ops use in production.
Episode 9: Running multiple environments with Docker Compose
Docker is great for density - running lots of containers on very little hardware. You particularly see that for non-production environments where you don’t need high availability and you don’t have a lot of traffic to deal with.
This episode shows you how to run multiple environments - different configurations of the same application - on a single server. It covers more advanced Compose topics like override files and extension fields.
You’ll also learn how to apply configuration to your apps with different approaches in the Compose file, like this docker-compose.yml example:
version: "3.7"
services:
todo-web:
ports:
- 8089:80
environment:
- Database:Provider=Sqlite
env_file:
- ./config/logging.debug.env
secrets:
todo-db-connection:
file: ./config/empty.json
The episode has lots of examples of how you can use Compose to model different configurations of the same application, while keeping your Compose files clean and easy to manage.
Episode 10: Building and testing applications with Docker and Docker Compose
Containers make it easy to build a Continuous Integration pipeline where every component runs in Docker and you can dispense with build servers that need careful nurturing.
This epsiode shows you how to build a simple pipeline using techniques you learned in earlier episodes - like multi-stage Dockerfiles - to keep your CI process portable and maintainable.
You’ll see how to run a complete build infrastructure in containers, using Gogs as the Git server, Jenkins to trigger the builds, and a local Docker registry in a container. The exercises focus on the patterns rather than the individual tools, so all the setup is done for you.
The easy way to keep your pipeline definitions clean is to use Docker Compose to model the build workflow as well as the runtime spec. This docker-compose-build.yml file is an override file which isolates the build settings, and uses variables and extension fields to reduce duplication:
version: "3.7"
x-args: &args
args:
BUILD_NUMBER: ${BUILD_NUMBER:-0}
BUILD_TAG: ${BUILD_TAG:-local}
services:
numbers-api:
build:
context: numbers
dockerfile: numbers-api/Dockerfile.v4
<<: *args
numbers-web:
build:
context: numbers
dockerfile: numbers-web/Dockerfile.v4
<<: *args
Of course you’re more likely to use managed services like GitHub and Azure DevOps, but the principle is the same - keep all the logic in your Dockerfiles and your Docker Compose files, and all you need from your service provider is Docker. That makes it super easy to migrate between providers without rewriting all your build scripts.
This episode also covers the secure software supply chain , extending your pipeline to include security scanning and signing so you can be sure the containers you run in production are safe.
Coming next
Week 2 covered multi-container apps, and in week 3 we move on to orchestration. We’ll use Docker Swarm which is the production-grade orchestrator built into Docker. It’s simpler than Kubernetes (which needs it’s own series - Learn Kubernetes in a Month of Lunches will be televised in 2021), and it uses the now-familiar Docker Compose specification to model apps.
You can always find the upcoming episode at diamol.net/stream and there are often book giveaways at diamol.net/giveaway.
The live stream is running through September 2020 and kicks off on Elton Stoneman’s YouTube channel weekdays at 19:00 UTC. The episodes are available to watch on demand as soon as the session ends.
Hope you can join me and continue to make progress in your Docker journey :)
Comments