
Windows Weekly Dockerfile #16: SQL Server
There are 52 Dockerfiles in the source code for my book, Docker on Windows. Perfect for a year-long blog series.
Each week I’ll look at one Dockerfile in detail, showing you what it does and how it works. This is #16 in the series, where I’ll look at packaging a custom SQL Server database schema into a portable Docker image.
SQL Server in Docker
You can run SQL Server in Docker, running your own database in a container which starts in seconds. You don’t need any version of SQL Server installed on your machine - you only need Docker.
Microsoft provide Docker images for SQL Server 2016 and 2017 on Windows - for both Developer Edition and Express Edition.
You can also run SQL Server 2017 in Docker on Linux, which is a supported configuration for production deployments.
The Microsoft images give you a clean, fresh install of SQL Server. So if you want to try out the GA release of SQL Server 2017, you can start Docker for Windows and run a database container:
docker container run `
-d -p 1433:1433 `
--name sql-db `
-e sa_password=DockerCon! `
-e ACCEPT_EULA=Y
microsoft/mssql-server-windows-express:2017-GA
That starts a SQL Server container running, which you can access from other Docker containers and from remote clients. The environment flags in the run command set the admin account password, and accept the SQL Server EULA.
Using the --name flag means any containers in the same Docker network can access the database using sql-db as the server name in the connection string. Publishing port 1433 with the -p flag means you can connect to the database container from a remote client, just like any other database server.
Sqlectron is a nice, lean SQL client which you can use to connect to the container:
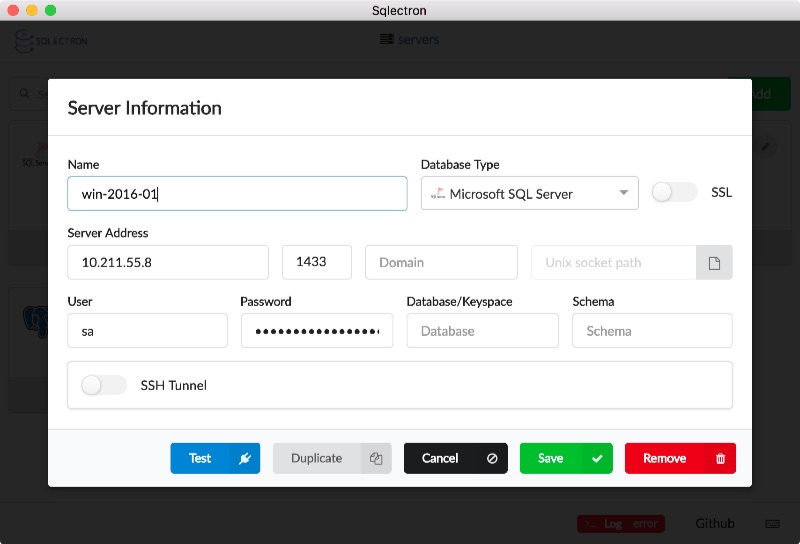
The server address I’m using is for the Windows Server 2016 VM I use for running Windows containers on my Mac. So the client connects to the VM on port 1433, and Docker directs traffic into the SQL container.
You can use SQL Server Management Studio, Visual Studio, VS Code or any other SQL Server client to connect in the same way. Then you can run a query to see the host info:
SELECT host_platform, host_distribution, host_release
FROM sys.dm_os_host_info;
That shows SQL Server is running on Windows Server version 10:
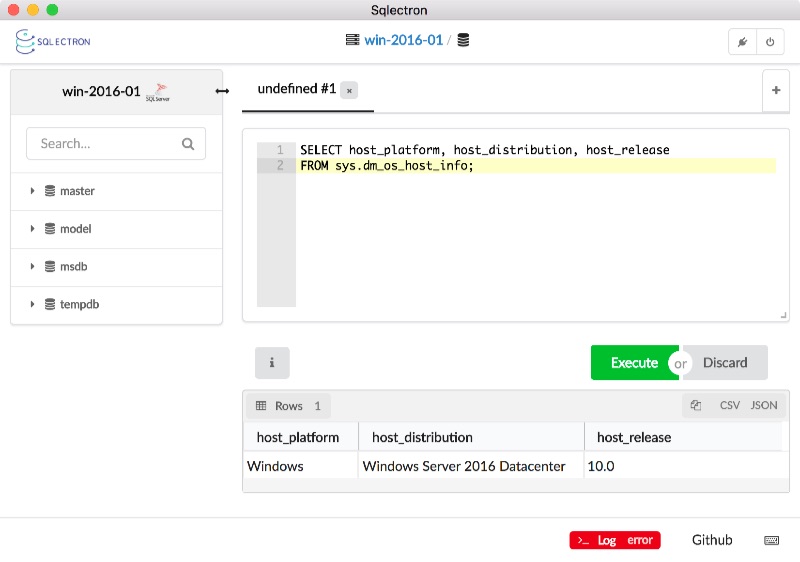
Sqlectron also lists the databases on the server - it shows the standard master, model, msdb and tempdb databases from a clean SQL Server install.
Running databases in containers becomes much more useful when you package your own database schema, which is what this week’s Dockerfile is all about.
The Dockerfile
This week’s image deploys a custom database schema on top of Microsoft’s SQL Server Express Docker image. I use SQL Server Data Tools ( SSDT ) to define the schema in a SQL project. The Dockerfile uses multi-stage builds to compile the SQL project and package the schema.
The builder stage starts with a Docker image with .NET, MSBuild and the SSDT deployment packages already installed, then it just builds the SQL project:
FROM sixeyed/msbuild:netfx-4.5.2-ssdt AS builder
WORKDIR C:\src\NerdDinner.Database
COPY src\NerdDinner.Database .
RUN msbuild NerdDinner.Database.sqlproj `
/p:SQLDBExtensionsRefPath="C:\Microsoft.Data.Tools.Msbuild.10.0.61026\lib\net40" `
/p:SqlServerRedistPath="C:\Microsoft.Data.Tools.Msbuild.10.0.61026\lib\net40"
When this stage completes, it generates a Dacpac which contains a model for deploying the schema, and all the SQL scripts in the project.
The second stage configures the custom database image, setting default environment variables and copying in the Dacpac and a PowerShell deployment script:
FROM microsoft/mssql-server-windows-express:2016-sp1
ENV ACCEPT_EULA="Y" `
DATA_PATH="C:\data" `
sa_password="N3rdD!Nne720^6"
VOLUME ${DATA_PATH}
WORKDIR C:\init
COPY Initialize-Database.ps1 .
CMD powershell ./Initialize-Database.ps1 -sa_password $env:sa_password -data_path $env:data_path -Verbose
COPY --from=builder C:\docker\NerdDinner.Database.dacpac .
The approach here is similar to Docker’s SQL Server lab, which you can follow along for a more detailed look.
The Dockerfile is simple, and the smart stuff happens in the PowerShell script. That runs when the container starts and it does this:
- checks if any database and log files (
.mdfand.ldf) exist at the expected data location - if no files exist, it deploys a new database using the model in the Dacpac
- if files do exist, it attaches the existing database and upgrades it to the model in the Dacpac.
That lets you run the database in different ways, to support different scenarios.
Usage - Disposable Database Containers
You can run a simple container without any Docker volumes, and that gives you a disposable database container:
docker container run `
-d -p 1433:1433 `
--name nerd-dinner-db `
dockeronwindows/ch03-nerd-dinner-db
Connect to the database container from a SQL client and you’ll see the Nerd Dinner schema deployed - the custom tables for dinners and RSVPs, and the ASP.NET membership tables:
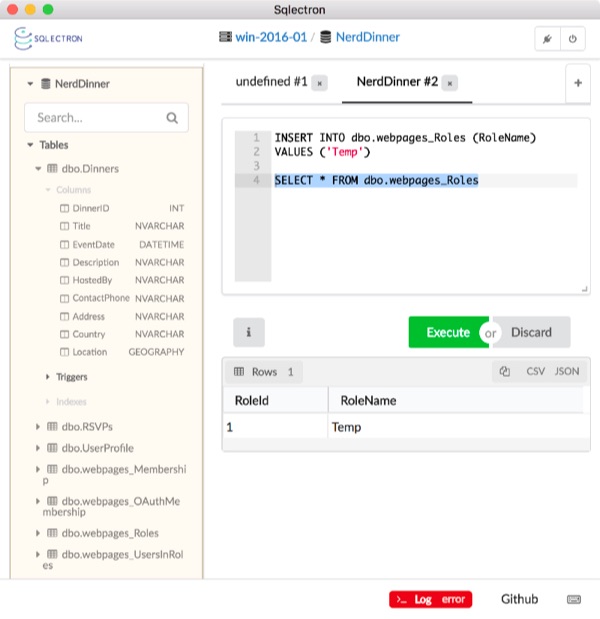
There are no post-deployment scripts in this SQL project, so the tables are all empty. You can insert a row into the Roles table from the client:
INSERT INTO dbo.webpages_Roles (RoleName)
VALUES ('Temp')
And you can run an interactive command in the Docker container to check that the row has been inserted:
docker container exec `
nerd-dinner-db `
powershell "Invoke-SqlCmd -Database NerdDinner -Query 'SELECT * FROM webpages_Roles'"
You’ll see output like this:
RoleId RoleName
------ --------
1 Temp
The database files are stored in the container’s writeable layer (which I covered back in Windows Weekly Dockerfile #7), which means the data will be lost when you remove the container.
This approach - the disposable database container - is perfect for development. Devs can each run their own instance of the app database in a lightweight container, and reset data to the initial state just by replacing the container.
And this is also great for integration tests in the CI pipeline. You can have real end-to-end tests which really write data to the database and check that it’s really there. Each test can use its own database container which starts in seconds with known state, so your tests won’t take ages to run, and won’t interfere with each other.
Usage - Persistent Database Containers
Disposable databases aren’t useful in every scenario :) But the initialize script lets you use this same image to run a persistent database container, where the data files are stored in a Docker volume outside of the container:
mkdir -p C:\databases\nerd-dinner
docker container run `
-d -p 1433:1433 `
-v C:\databases\nerd-dinner:C:\data `
--name nerd-dinner-db `
dockeronwindows/ch03-nerd-dinner-db
The first time you run that, the .ldf and .mdf files are created on the host, in the C:\databases\nerd-dinner directory which is used for the container volume. The script deploys the database schema, configured to write the data files to that directory (which is actually C:\data inside the container).
You can insert data and remove this container, and the data files still exist on the host. When you run a new container mapping the same volume, the existing database files get attached and the new database container has all the old container’s data.
This supports two scenarios:
server updates - you can run a new container with an updated version of the Windows base image, or a patched version of SQL Server, and your existing database will run in the same way;
schema updates - you can make changes to the SQL project and build a new version of the Docker image. The initialize script uses the SqlPackage tool to deploy the database from the Dacpac, so that generates a diff script and upgrades the existing database schema to match the new model.
This is perfect for non-production databases. You can have persistent database containers for every test environment, with each one using the version of the database image that matches the version of the application under test. You can upgrade the database as part of the CI/CD process and still retain all the test data from the environment.
You could extend the initialize script to use a parameter for the target database to upgrade. That way you could run a container which has your tested database schema to deploy changes to your existing production SQL Server, running on a VM or in the cloud.
Packaging your SQL Server schema in a Docker image means you use the same artifacts as the rest of your application - with consistent versioning, storage and deployment. I use Dacpacs for the schema in this example, but you can package custom SQL scripts or whatever deployment tools you currently use. It’s a powerful way of bringing your database into the CI/CD pipeline.
Next Up
This week’s image deploys the SQL Server database for Nerd Dinner in a Docker container. Next week I’ll walk through an updated version of the Nerd Dinner web application, which is configured to use the SQL Server container for storage.
That’s ch03-nerd-dinner-web, coming next.
Comments